Occlusion-Aware Video Object Inpainting

| Input | STTN (ECCV'20) | FGVC (ECCV'20) | VOIN |
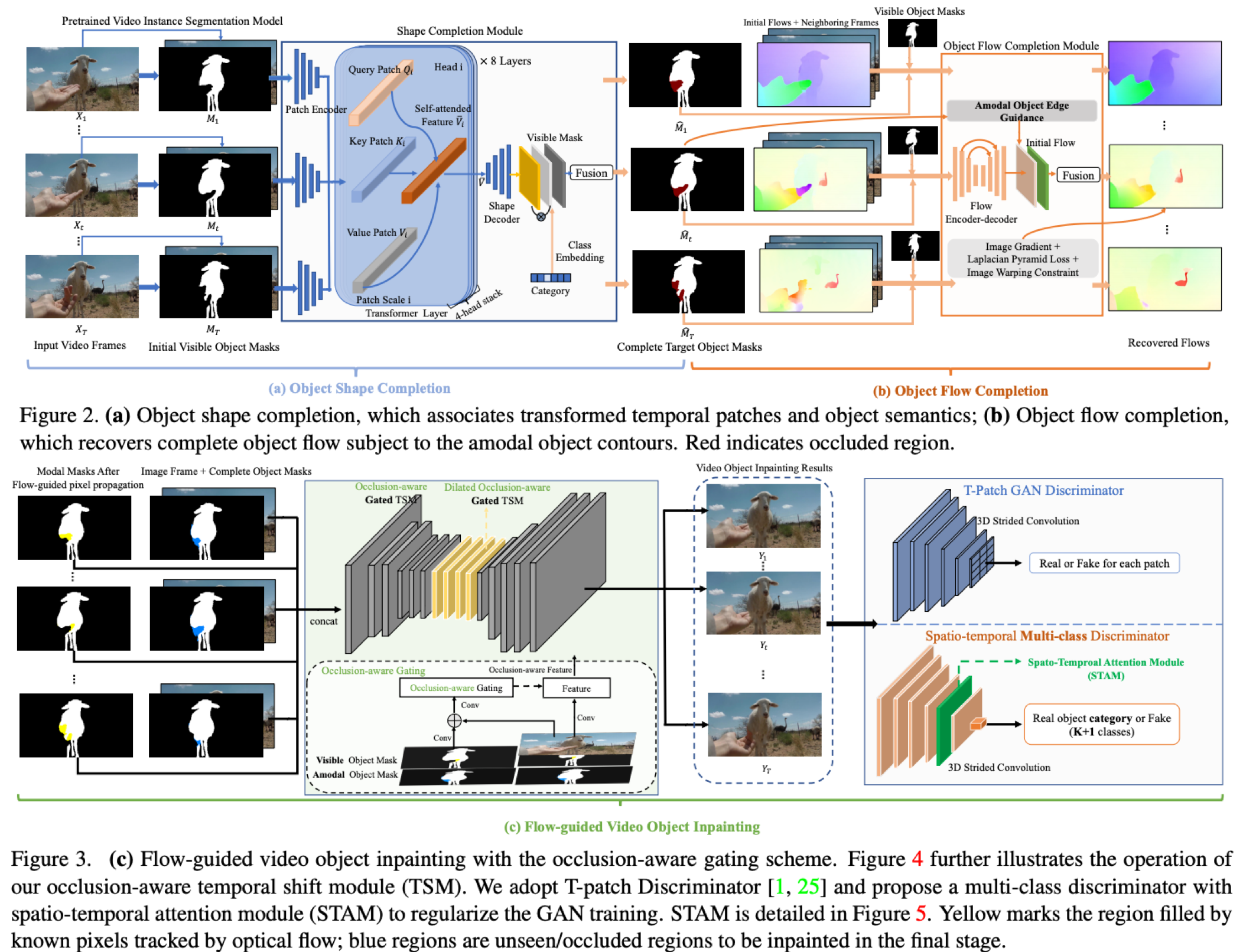
Conventional video inpainting is neither object-oriented nor occlusion-aware, making it liable to obvious artifacts when large occluded object regions are inpainted. This paper presents occlusion-aware video object inpainting, which recovers both the complete shape and appearance for occluded objects in videos given their visible mask segmentation.
To facilitate this new research, we construct the first large-scale video object inpainting benchmark {\em YouTube-VOI} to provide realistic occlusion scenarios with both occluded and visible object masks available. Our technical contribution VOIN jointly performs video object shape completion and occluded texture generation. In particular, the shape completion module models long-range object coherence while the flow completion module recovers accurate flow with sharp motion boundary, for propagating temporally-consistent texture to the same moving object across frames. For more realistic results, VOIN is optimized using both T-PatchGAN and a new spatio-temporal attention-based multi-class discriminator.
Finally, we compare VOIN and strong baselines on YouTube-VOI. Experimental results clearly demonstrate the efficacy of our method including inpainting complex and dynamic objects. VOIN degrades gracefully with inaccurate input visible mask.
1) Step One:
2) Step Two:
YouTube-VOI benchmark contains 5,305 videos (4,774 for training and 531 for evaluation) with resolution higher than 640x480, a 65-category label set including common objects such as people, animals and vehicles, and over 2 million occluded and visible masks.
The mask annotation folders under each video object:
1) full_mask: the sequential complete mask of an interested video object (occludee, modal annotations).
2) occ_mask: the sequential invisible (occluded part) mask of an interested video object.
3) occ_mask_full: the sequential complete mask of the video occluder object.
4) remain_mask: the sequential visible (remaning part) mask of an interested video object.
@inproceedings{ke2021voin,
author = {Ke, Lei and Tai, Yu-Wing and Tang, Chi-Keung},
title = {Occlusion-Aware Video Object Inpainting},
booktitle = {The IEEE International Conference on Computer Vision (ICCV)},
year = {2021}
}